什么是分布式ID ?
单库单表/分库分表时,要求每一条记录都有唯一标识,保证向下游的传输数据中有唯一标识。生成这个唯一标识的服务叫做「分布式 ID 服务」。
分布式的两层含义:ID 服务本身是多实例部署;ID 生成请求来源有多个服务实例。
分布式ID的主要作用是,唯一标识一条记录,为幂等等业务需求铺路。
下文中,
分布式ID、全局唯一标识可以看成相同的概念。分布式ID服务和IDService含义相同。
我们用一个业务场景来讨论如何实现分布式ID服务:
如果一个业务的数据使用 MySQL 存储,基于用户ID进行分库分表,每一条数据都需要分配一个在这个业务中的全局唯一ID,如何实现全局唯一 ID ?
探讨方案前,先讨论下面两个点:
一、用数字,还是用字符串?
下面的方案中既有用数字当全局唯一ID,也有用字符串作为全局唯一ID的。数字存储空间小,性能相对较高,但是取值范围有限,也很难有语义化的值。字符串与之相反。具体使用哪种,根据场景决策。
二、如果这个ID是对外暴露的,比如是用户订单号,要考虑下面两点后再选择方案:
- 不能暴露敏感信息,比如不能把用户ID放到订单号里;
- 不能让别人猜到你的数据量。比如用的步长为1进行递增的全局ID,竞争对手早上下单一次,晚上下单一次,就知道当天的下单量了。
方案1:用户ID + 自增主键
一个简单的方案是,全局唯一 ID 用字符串类型,由 用户ID 和 自增主键的值组成。例如有一条记录,用户ID为1234,自增主键值是32,那么全局唯一ID便是1234-12。
为什么这个方案里全局唯一ID不用数字类型?很简单,用户1234有一条记录的自增主键是56,那么全局唯一ID就是123456;用户123有一条记录的自增主键是456,那么全局唯一ID也会是123456,这就有问题了。
所以用字符串。
但这个方案是有问题的。因为和自增主键产生了耦合。为什么呢?
原因1:需要两步才能把全局唯一ID放进去,第一步是插入不包含全局ID的数据,并得到主键ID;第二步是组装全局ID,并update到记录中。(这只能说是个小问题)
原因2:后续迁移数据很麻烦。比如原先用 32 张分表储存数据,后来发现不够用,改用 128 张分表。这种情况下需要将 原先的 32张分表数据不断的向新的 128张分表迁移,但新的128张分表有有自己的自增主键。这会导致迁移很麻烦,比如:
- 在新表中全局ID保持不变,但是主键ID要和旧表ID保持一致吗?如果保持一致,新表中会浪费一些自增主键,能接受吗?
- 如果迁移过程中必须保证业务可用,新增加的数据在新的分表和旧的分表中的自增主键和全局唯一ID如何保持一致?
迁移数据是个很大的话题,这里只抛出问题,不做讨论。
我的观点是:不要让主键自增ID,有业务含义。包括不要用它当业务上的唯一标识。
方案2:UUID
用 UUID 的话,全局唯一ID必须是字符串类型。
~~持保留意见,因为对我来说是个黑盒,我不知道在一个较长时间内会不会出现重复,出现时间回拨等异常的情况下会不会出现重复。~~
在 [维基百科](https://en.wikipedia.org/wiki/Universally_unique_identifi er) 上,有一段描述,说明了 UUID 无法完全保证不冲突:
While the probability that a UUID will be duplicated is not zero, it is close enough to zero to be negligible.
如果极低概率的重复出现时,对业务并无影响,那么这是一个可选的方案。
方案3:单点全局唯一ID
例如,新建一个带MySQL表(就叫 global_id吧),表里面只有一条记录,记录着当前的全局唯一id,初始值为0。每当业务方需要一个全局唯一ID时,按照下面逻辑生成:
- 进入数据库事务
- 通过update对global_id表中的数据加1。(这一步会对数据加上排他锁,事务结束后才释放)
- 读取当前全局id值
- 提交事务
- 返回全局唯一id
在 Leaf——美团点评分布式ID生成系统 中给出了一个用数据库自增主键的方案,但思路是相同的:
- 进入事务
- 用replace覆盖掉当前数据
- 获取自增主键值作为全局唯一ID
- 提交事务
- 返回全局唯一ID
以上,可以封装成一个 IDService 服务。
zookeeper 有个顺序节点功能,也可以实现。
问题是:单点,性能差,可用性低。
方案4:snowflake
Snowflake 算法用于生成单调递增的long数字类型ID。
long类型数字,8字节,64比特,被拆成多个段:
| 比特数 | 段名 | 说明 |
|---|---|---|
| 1 | 符号位 | 保持为0。 |
| 41 | 毫秒级时间戳 | 2^41 = 2199023255552,可以标识从0到2199023255551,2199023255551对应的时间是2039-09-07 23:47:35。也就是从 2019 年算,还能用20 年。但这个时间戳是相对1970年的,我们可以优化成相对2019年,这样就可以用接近70年。 |
| 5 | 数据中心ID | 2^5=32,支持32个数据中心。但是一般没有这么多数据中心,可以不用或者用2比特。多出的比特位送给下面的workId。 |
| 5 | workerID | 2^5=32,可以认为用来标识同一个服务的多个进程实例。在现在的微服务背景下,一个服务32个实例可能不够用,所以可以向上面的数据中心ID要几个比特位。注意,数据中心ID+workerId千万不能重复使用,否则做不到全局唯一。 |
| 12 | 毫秒级流水号 | 2^12=4096。这个是自增的部分。 |
这个算法可以内嵌到业务方代码中,也可以单独做出来一个服务供业务方调用。
数据中心ID和workerID如何指定 ?
数据中心ID+workerID不能重复,否则做不到全局唯一,那么怎么给一个服务实例指定呢?数据中心ID这个是可以提前确定的,作为环境变量传给服务即可。所以我们主要看workerID如何指定。有这样几个方案:
一、服务启动时手动指定。
二、引入zookeeper顺序节点,服务启动时从zookeeper拿到顺序ID作为workerID,并持久化到本地。(有个问题,如果该服务实例被摘除,如何回收workerID?)
三、用更多bit存workerID,用完即走。例如uid-generator 用了 22 bit ,这样可以支持 2^22 = 4194304 个workerID。从0开始分配workerID,不停递增,最新的workerID记录在数据库中。服务实例启动时获取workerID,服务重启,则重新获取workerID。(同样的,没解决回收的问题。用更多bit存workerID,意味着其他段变短,uid-generator 用 28bit存秒级时间戳,22比特存workerID,13比特存秒级流水号)
四、用机器ip去算一个workerID。这是个很不明智的选择,因为早晚会遇到冲突的情况,比如 从一次 Snowflake 异常说起。
另外一点要注意的是,workerID限制了服务实例的数量。
说了这么多,snowflake 算法长什么样?
可以看下 SnowFlake.java 的实现,很简单。还有很多同学造过这个轮子:
注意算法中一个很重要的点:当前毫秒时间戳内的流水号使用完后,若仍需要马上生成新的全局ID,要等到下一毫秒,再继续从0开始生成流水号。这个等到下一毫秒,不需要用sleep,之间勇哥死循环不定获取当前时间就行。
还有一个点,如果服务运行过程中,发现时间回拨,建议返回失败,并告警。
时钟回拨,影响很大!
在服务运行过程中发生时间回拨,我们可以返回失败。但是若服务重启后发生时间回拨了呢?举个例子,服务在每一秒都会向业务方生成全局唯一ID,在服务器时间是2019-01-26 22:40:29服务因异常而重启,重新提供服务时服务器时间是2019-01-26 22:40:28,竟然在 2019-01-26 22:40:29 之前!这种时间的不合理变化(至少对于snowflake不合理)可能是因为:
- NTP 同步时间
- 人工修改时间
把上面两件事情禁止掉就能解决。
还有一个解决方案是,将当前时间(秒级)持久化到硬盘。服务异常重启时,用当前时间和硬盘上存的时间作比较,若小于等于硬盘上时间,则等到下一秒,等到当前时间大于硬盘记录的时间,再提供服务。
方案5:预取
这个方案对应 Leaf——美团点评分布式ID生成系统 中的 Leaf 方案,可以看做本文中方案3的优化。
我们将提供ID的服务称作 IDService,当业务方请求 IDService 提供一个全局ID时,IDService不再像方案3那样让数据库生成一个新ID,而是从服务实例中存储的数据库预先生成的一堆ID中取出一个返回给业务方。
假设MySQL表(还叫 global_id吧),表里面只有一条记录,记录着当前的全局唯一id,初始值为0,预取的步长是1000 ,IDService 可以这样设计:
IDService 服务启动时,将 global_id 表中全局id加1000,并将0~999这1000个数字放在内存中(例如 Java中的queue,可以顺序放,也可以打乱顺序再放进去)。此时数据库中记录的全局 ID 是 1000。
业务方向 IDService 请求全局唯一ID时,若IDService实例中还有ID,则取出,返回给业务方;若没有,则将 global_id 表中全局id加1000,并将1000~1999这1000个数字放在内存中。此时数据库中记录的全局 ID 是 2000。
这个方案中,数据库更新时,IDService 会变慢,所以 Leaf 用了双 buffer 进行优化。原先用一个 Java Queue 保存预取的1000个ID,现在改成用两个 Java Queue ,都存1000个预取的ID。我们将两个 Java Queue 分别命名为Q1、Q2。
双buffer方案:
- IDService 服务启动时,将 global_id 表中全局id加1000,并将0~999这1000个数字填充到Q1中;将 global_id 表中全局id加1000,并将1000~1999这1000个数字填充到Q2中;(例如 Java中的queue,可以顺序放,也可以打乱顺序再放进去)。此时数据库中记录的全局 ID 是 2000。两个队列,默认从 Q1 取ID。
- 业务方向IDService请求全局唯一ID时,发现现在设定为从Q1中取ID,于是尝试从 Q1 中取 ID。若有则取出,返回给业务方;若Q1中没有ID了,则切换为默认从 Q2 取ID,返回给业务方。同时,异步向Q1中填充ID:将 global_id 表中全局id加1000,并将2000~2999这1000个数字填充到Q1中。此时数据库中记录的全局 ID 是 3000。
- 类似的,若Q2中没有ID了,则切换为默认从Q1取ID,并异步向Q1中填充ID。
双 buffer 方案也可以用在下面几个基于预取的方案中。
该方案中仍使用了一个数据库,是单点,如何提升可用性?Leaf 方案中给了两个方案:
- 可以用主从架构部署数据库,主库出问题后切换到从库。但是极端情况下主从同步会导致问题。
- 选择使用“类Paxos算法”实现的强一致MySQL方案。
方案6:snowflake + 预取
这个方案对应 Leaf——美团点评分布式ID生成系统 中的 Leaf+segments 方案。
在这个方案中,去除对数据库的依赖,使用 snowflake 生成ID,但不是一个一个的生成,而是像方案5那样预取,这样可以进一步提升性能。
那么如何解决异常重启后时间回拨的问题?
Leaf+segments 方案给出的解决办法是,每3秒将机器时间持久化,服务启动时将当前时间和之前持久化的时间比较,若小于,则等待或者直接启动失败。
这里也有一个问题,就是一定要保证时间戳不能出现极大波动,例如,千万不要出现运维事故,导致机器时间变成100年以后。其他方案,也应该评估下该风险。
方案7:基于多数据库的高可用方案1
方案5中只用了一个数据库,可用性不高,可以用多个数据库提升可用性。举个例子:
我们用2个数据库,数据库1只能取奇数,数据库2只能取偶数。
- 预取ID时,可以随机选一个数据库,也可以用轮询选择数据库。
- IDService 发现一个数据库不可用时,可以临时摘除掉。
如果要更多数据库,比如3个数据库,那么数数据库1只能生成1,4,7,10等ID,数据库2只能生成2、5、8、11等ID,数据库3只能生成3、6、9、12 等ID。
如果是在现有2个数据库的基础上再扩充,可以将数据库1拆成两个,分别是数据库1-1、数据库1-2,数据库1-1的取值是 1、5、9等等,数据库1-2的取值是3、7、11等等。类似的,将数据库2拆成两个,分别是数据库2-1、数据库2-2,数据库2-1的取值是2、6、10等等,数据库2-2的取值是4、8、12 等等。
这套方案来自 Flickr 。
方案8:基于多数据库的高可用方案2
假如用字符串做 ID,ID全部由数字组成 ,我们这样设计ID:
| 字符数 | 段名 | 描述 |
|---|---|---|
| 10 | 时间(年的后两位+月+日+时+分) | 例如,2019年01月27日09:48,对应1901270948 |
| 2 | 数据库编号 | 支持00~99 |
| 10 | 流水号 | 从0000000000到9999999999 |
我们用100个数据库来生成ID,每个数据库中一张表,每一分钟对应一条记录。例如我们在编号为12的数据库创建表:
CREATE TABLE `id_info` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`db_index` CHAR(2) NOT NULL DEFAULT '12', -- 数据库编号
`current_minute` CHAR(10) NOT NULL , -- 当前时间,分钟级,如1901270947
`sequence` bigint NOT NULL DEFAULT 0, -- 流水号
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8mb4
当 IDService 用步长1000 从数据库预取 ID 时:
- 随机选择一个数据库,例如选择了编号12的数据库
- 找到当前时间(分钟级,例如是 1901270947 )对应的记录,无则创建。
- 对 sequence 增加1000,IDService 将1901270947120000000000到1901270947120000000999存到内存。
如何保证高可用呢?
- 一个分库在一分钟内生成10000000000 个ID,正常业务是用不完的。
- 若有数据库出现问题,IDService 将其临时摘除即可。
对于上面的第1点,如果这一分钟的真用完了怎么办?两个策略:
- 抛出错误,等待下一分钟到来再重新获取ID
- 借用下一分钟的ID。
数据量分析:
如果数据库每分钟生成一条记录,一天有24*60=1440条记录,一年会产生525600条记录。可以定期删除较旧数据。
为什么说如果数据库每分钟生成一条记录?如果ID消费很慢,会导致有些分钟没有对应的记录。
如果删除数据后出现时间跨度的时间回拨怎么办?那就把允许使用的时间最小值记录下来,每次删除数据,更新下这个最小值即可。
方案9:基于多数据库的高可用方案3
这里我们假定要做一个long类型的全局ID。我们知道:
秒级时间戳目前只用了10个数字,例如 1548563250 (对应时间是 2019-01-27 12:27:30) 。 63 bit比特能表示的最大数字是9223372036854775807,由19个数字组成。
基于上面两点,我们可以这样组装一个long类型全局ID:
| 十进制数字数 | 段名 | 描述 |
|---|---|---|
| 10 | 秒级时间戳 | 例如,1548563250 对应 2019-01-27 12:27:30 。 最大值是 9223372036 ,对应 2262年 |
| 2 | 数据库编号 | 支持从 00 到 99 |
| 7 | 流水号 | 支持从 0000000 到 9999999 |
我们用100个数据库来生成ID,每个数据库中一张表,每一分钟对应一条记录。例如我们在编号为12的数据库创建表:
CREATE TABLE `id_info` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`db_index` int NOT NULL DEFAULT 12, -- 数据库编号
`current_timestamp` int NOT NULL DEFAULT 0, -- 当前秒级时间戳,最大值是 9223372036
`sequence` int NOT NULL DEFAULT 0, -- 流水号,最大值是 9999999
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8mb4
在这个方案里,每张表只有一条数据。
设定步长为1000,IDService 用以下方案预取全局ID:
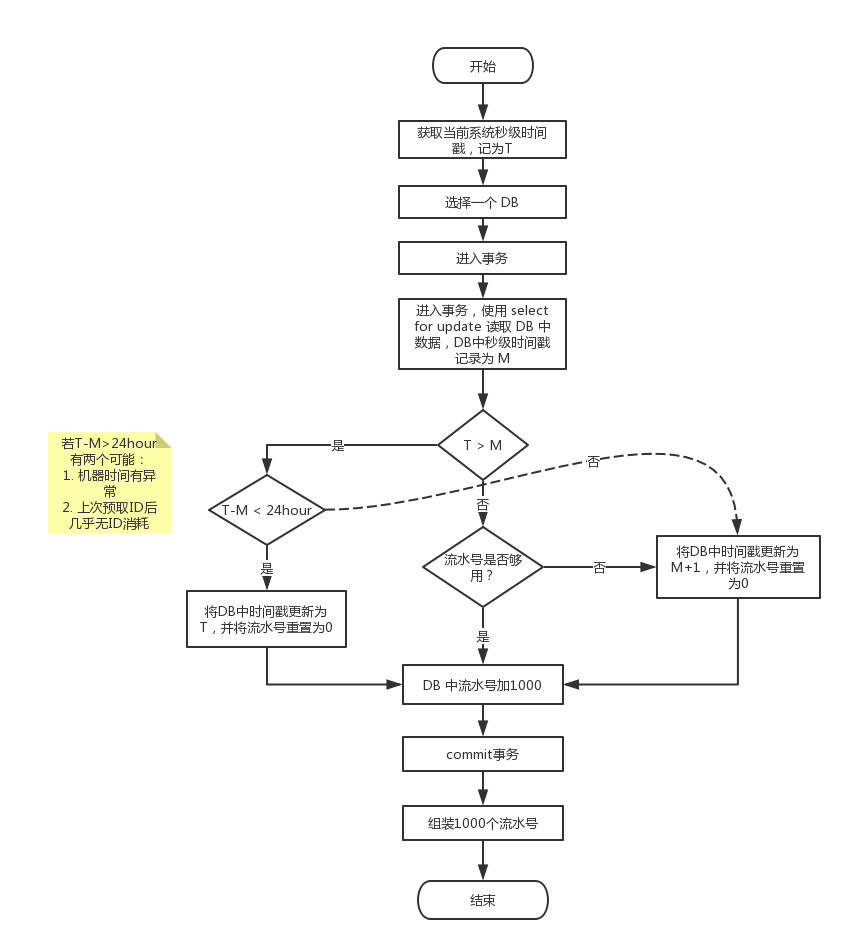
- 对于 T 远大于 M 的情况,有两种可能的原因,一个是ID消费的很慢,一个是系统时间出现异常(这种情况要告警)。为了消除ID 消费太慢的情况,IDService 可以每5分钟检测下当前存的ID对应的时间,若是5分钟之前,则强制重新预取 ID。
- 当T<=M,流水号又已经分配完时,向前借1秒。
- 为了降低DB操作,也可以一次预取更多的全局ID,比如一次取 100000 个全局ID。
参考
- 分布式唯一id:snowflake算法思考
- Leaf——美团点评分布式ID生成系统
- 如果再有人问你分布式 ID,这篇文章丢给他
- github - uid-generator
- github - SnowFlake.java
- github - id-generator
- github - DistributedID