字符集、代码点、代码单元
将所有的字符放在一起就是字符集。例如将所有的英文字母放在一起可以组成一个字符集,将所有的英文字母和一些标点符号放在一起可以组成一个字符集,将所有的汉字放在一起可以组成一个字符集,将所有的英文字母以及汉字放在一起也可以组成一个字符集。
对一个字符集中的所有字符进行编号(整数的序号),每个字符的编号在这个字符集里都是独一无二的。例如,由所有英文字母组成的字符集中有52个字符(小写字母26个,大写字母26个),可以将这些字符依次编号为0、1、2、...、51。一个字符的编号称为该字符的代码点(Code Point)。这种编码后的字符集叫做编码字符集。常见的编码字符集有ASCII、Unicode、GBK、UTF8等。
Unicode 本身只给出了字符和字符编号,没有给出存储方式。UTF-8、UTF-16 等编码字符集基于 Unicode 实现,并给出了存储方式。
代码单元(Code Unit)是编码时使用的最小单元。这个和如何存储一个字符的编码有关。以为下文将提到的UTF-8为例,其代码单元是8bit,由于UTF-8是变长编码,这意味着在UTF-8有些字符用8bit来存储和表示,有些是8×2bit存储和表示,还有8×3bit等等。
Unicode
Unicode的目标是包含世界上所有语言的文字。Unicode 6.0中已经包含了超过109 000个字符。要了解Unicode,先给出下面的等式:
2^16 = 6_5536
17 × 65536 = 111_4112
0x10FFFF = 111_4111
Unicode个定义了1 114 112个代码点,值的范围是0~0x10FFFF。这些代码点当前只被使用了一小部分。
Unicode被分为17个区域,一个区域叫一个平面(plane),每个平面有65 536个字符。0x10FFFF的最高两位为0x10,由0到0x10,刚好17个平面,每个平面是16进制表示的最低4位是从0x0000到0xFFFF。
第一个平面的范围是0x000000到0x00FFFF,叫做基本多语言平面(BMP),包含了最常用的字符和符号。第2、3、4平面作补充了一些字符。第5到14个平面尚未分配。第15个平面主要包含非非图形化字符。第16、17个平面叫做私有使用区域平面(PUA),供第三方自定义。
Unicode 兼容 ASCII 。
如何表示和存储Unicode
一个比较简单的思路是,既然Unicode代码点的值的范围是0~0x10FFF,那么可以直接用3个字节来表示,即使用定长的3个字节来表示所有Unicode代码点对应的字符。但是这存在一个空间使用的问题,例如对于使用英语的人而言,ASCII基本可以满足他的使用。如果使用ASCII,只需要1个字节来存储和表示字符,如果使用Unicode的3个字节来存储,显然是浪费空间的。那么让我们来看看现实中的编码方案。
UTF-8编码
UTF-8使用8bit作为一个代码单元,是变长编码。先看一下http://en.wikipedia.org/wiki/UTF-8给出的表格。
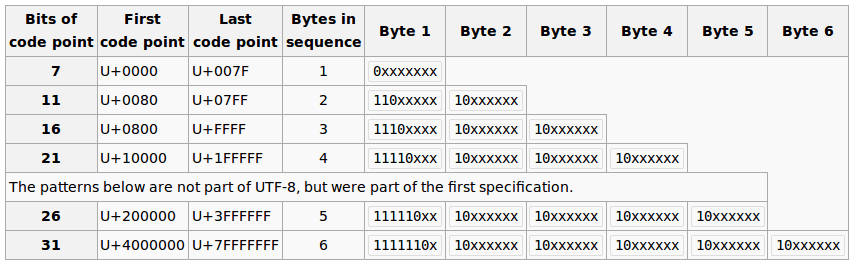
可以看出,Unicode中代码点可以用7bit表示的字符在UTF-8中均用1字节表示,代码点可以分别用8到11(8、9、10、11)bit表示的字符在UTF-8中均用2字节表示,依次类推。总的来说UTF-8与Unicode兼容,但是可以表示比目前的Unicode更多的字符。
下面举例说明UTF-8与Unicode的映射方式。
汉字“你”的Unicode代码点是Ox4F60,其二进制形式(下划线用于优化阅读体验,无特殊意义):
0100_1111 0110_0000
至少需要15bit才能表示“你”,所以其对应的UTF-8编码需要3字节:
1110_0100 10_111101 10_100000
即E4BDA0。把每个字节_后的bit位提取出来放在一起,就是Unicode中对应的代码点了。
UTF-16
UTF-16使用16bit作为一个代码单元,是变长编码。首先记住这一点:在Unicode中,代码点0xD800~0xDFFF是没有定义字符的。
对于Unicode中代码点位于0x0000~0xFFFF中字符,UTF-16使用一个代码单元即可,那么对于Unicode中代码点不在0x0000~0xFFFF之间的字符呢?即对于Unicode中代码点位于0x10000~0x10FFFF中字符,UTF-16该怎么表示?
**思路是这样的:**使用两个代码单元来表示这些字符,其中第一个代码单元的值在0xD800~0xDBFF之间,第二个代码单元的值在0xDC00~0xDFFF之间,前者称为高位代理,后者称为低位代理,两者一起称为代理项对(surrogate pair)。
**下面计算UTF-16能否表示所有的Unicode字符。**使用一个UTF-16代码单元可以表示的字符数量是2^16,0xD800~0xDFFF对于Unicode或者UTF-16的一个代理单元都是不可用的。使用两个UTF-16代码单元可以表示的字符数量为:
(0xdbff-0xd800+1) * (0xdfff-0xdc00+1)
= 1024 * 1024
= 1048576
所以UTF-16可以表示的字符数量为:
1048576 + 2^16 = 1114112
这和Unicode表示的字符数量是相同的。
字符数量相同的前提是,在Unicode中,代码点0xD800~0xDFFF是没有定义字符的。 这个要确认下 Unicode 的规范是否永远不在该范围内定义字符。如果之前没有规范,以后想在该范围内加字符也几乎不可能。原因: 1、世界上没那么多字符。 2、Java 等编程语言影响力较大,会反对。
对于Unicode中代码点位于0x10000~0x10FFFF中字符,如何转化为代理项对? 首先,将代码点减去0x10000,这样新的代码点的范围变成了0~0xFFFFF,这些代码点可以用20bit来表示。将这20bit的前10bit(0~0x3FF)加上0xD800可得到高位代理,将这20bit的后10bit(0~0x3FF)加上0xDC00可得到低位代理。
对于utf-16还有字节序的问题(即大端序、小端序、混合序),可以参考维基百科-字节序。
UTF-32
一个代理单元是32bit,所以一个代码单元就可以表示所有的Unicode字符,是定长编码,与Unicode代码点一一对应。
UCS-2
定长编码,使用2个字节表示字符,是UTF-16的子集,只能表示Unicode中代码点位于0x0000~0xFFFF中字符。
Java的编码
java平台内部统一使用UTF-16编码。
// 文件是utf-8编码
public static void main(String[] args) throws UnsupportedEncodingException {
// “你” -> utf-8编码:E4BDA0 , unicode代码点:4F60
byte[] bs = new byte[]{(byte)0xE4, (byte)0xBD, (byte)0xA0};
String str = new String(bs, "UTF-8");
System.out.println(str); // 你
char c0 = str.charAt(0);
System.out.println( (int)c0 ); // 20320
System.out.println(Integer.toHexString( (int)c0 )); // 4f60
System.out.println(new String("你").equals(str)); // true
}
运行结果:
你
20320
4f60
true
0xE4等16进制表示的整数默认是int类型,由于只有8bit,所以是正数。将0xE4强制转换为byte,就是保留int的低8位。byte是有符号的,所以(byte)0xE4是负数。
String内部使用char数组存放数据,char是16bit,无符号,一个char相当于UTF-16的一个代码单元。new new String(bs, "UTF-8");将UTF-8编码的E4BDA0,转换成UTF-16表示。“你”的UTF-16表示是4F60,这也是Integer.toHexString( (int)c0 )的结果。
由于new String("你").equals(str)输出true,可以看出java自动将字符串"你"转换成为UTF-16编码。
相关资料
成富 《深入理解Java7 核心技术与最佳实践》 第四章 国际化与本地化