2014-12-22
问题
静态博客的确很不错,也有很好的服务,比如github可以帮忙托管博客。我最开始是使用wordpress写博客,然后被静态博客的简洁(以及不用担心博客托管的费用和管理)所吸引,改用了hexo。使用了一段时间后,发现简洁的同时也给我带来了管理上的不简洁,之后改用ghost博客,同时url也基本都改变了。
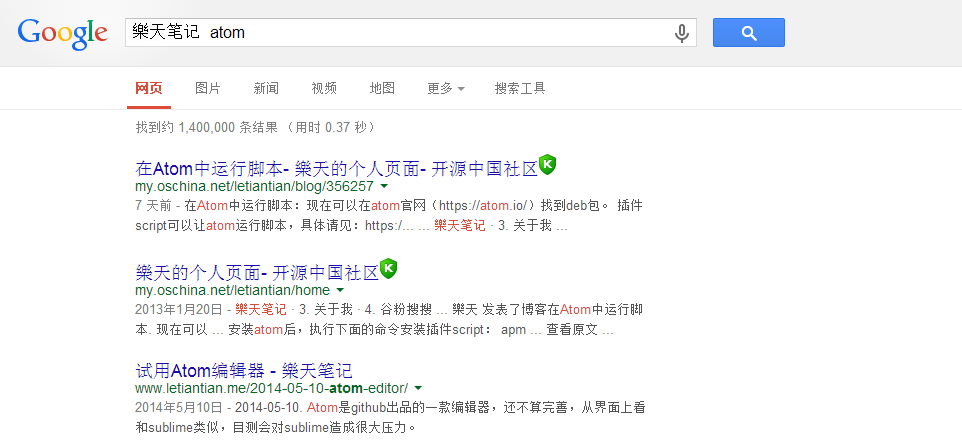
如果请求的url不存在,Ghost会返回404页面,响应状态也是404。然而过去了2个月左右,我在google搜索“樂天笔记 atom”,第一条仍然是已经不存在的页面,这篇文章现在的地址是http://www.letiantian.xyz/2014-05-10-atom-editor/。

怎么解决
谷歌站长工具支持删除url,但是一次只能删除一个,无法批量删除。在一个新闻组里也找到了类似的问题,回复中建议使用robots.txt来disallow不存在的url。我决定试一试。
如何修改Ghost的robots.txt
Ghost的默认robots.txt内容如下:
User-agent: *
Disallow: /ghost/
在使用的主题目录下加上自己的robots.txt即可。
如何找到不存在的url
hexo带有一个sitemap生成插件,可以用它来生成sitemap.xml,一般格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://letiantian.xyz/2014/10/04-asynchronous-requests/</loc>
<lastmod>2014-10-04T02:59:20.000Z</lastmod>
<changefreq>daily</changefreq>
</url>
<url>
<loc>http://letiantian.xyz/about/index.html</loc>
<lastmod>2014-05-01T14:38:19.000Z</lastmod>
<changefreq>daily</changefreq>
</url>
</urlset>
了解格式后,要做的就是从sitemap.xml提取出所有的url、并删掉url中的http://letiantian.xyz。
使用xml2js模块提取url:
关于xml2js:https://www.npmjs.com/package/xml2js。
$ npm install xml2js
# !/usr/bin/nodejs
var fs = require('fs'),
xml2js = require('xml2js');
var parser = new xml2js.Parser();
fs.readFile(__dirname + '/sitemap.xml',
function(err, data) {
parser.parseString(data,
function(err,result) {
urls = result.urlset.url;
for (var i = 0; i < urls.length; i++) {
console.log(urls[i].loc[0].replace(/http:\/\/letiantian.xyz/, ''));
}
}
);
}
);
结果:
/2014/10/04-asynchronous-requests/
/about/index.html
/machine-learning/2014/09-21-affinity-propagation/
/machine-learning/2014/09-20-meanshift-clustering/
/machine-learning/2014/09-18-logistic-regression/
/machine-learning/2014/09-18-gradient-descent/
/algorithm/2014/09-17-float-string/
/2014/09/16-nginx-tornado/
/blogroll/index.html
/2014/09/08-find-repeating-elements-in-array/
/2014/09/08-latex-complie-references-warning/
/machine-learning/2014/09-07-k-medoids/
/2014/09/06-variance-and-covariance/
/hello-world/
/algorithm/2014/09-02-arrange-activity/
/2014/08/30-ruby-thread-join/
/algorithm/2014/08-24-shuffle-algorithm/
/algorithm/2014/08-24-reservoir-algorithm/
/2014/08/24-install-and-config-ruby/
/2014/08/22-modernize-website-of-college/
......
据此,改写robots.txt即可。
更进一步,去除cat和tag。
等待结果
我在2014-12-14这一天修改了robots.txt。
若干天后。。。。今天: