2014-03-27
在 基于用户的协同过滤 和 基于物品的协同过滤 中在使用加权平均值方法时都有提到将相似度看作是权重。事实上基于欧几里得距离的相似度(或者说基于欧几里得距离的权重)的生成有多种方法。这些方法都是基于常见的递减函数。
反函数
y=1/x便是反函数,但是考虑到距离为0以及权重应在一个有限范围内,便改写为y = 1/(1+x)。
减法
如果距离是x,则权重为y=b-x,其中b是常数且为正数。如果y的值小于0,则y置为0;y不小于0,则保持原值。
高斯函数
资料[1]中给出了高斯函数的公式:
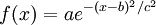
在实际应用中,多将a设为1,b设为0,这样f(x)在x>=0时,将从1开始递减,但不会跌向0。c的值根据喜好和需求设定即可。
代码实现与总结
#-*-encoding:utf-8-*-
import math
def get_euclidean_distance(dot1, dot2):
''' 根据欧几里得距离判断相似性'''
s = sum([pow(dot1[x] - dot2[x], 2) for x in range(len(dot1))])
return math.sqrt(s)
def inverse_weight(distance):
''' 基于反函数的权重'''
return 1.0 / (1.0 + distance)
def subtraction_weight(distance):
''' 基于减法的权重 '''
result = 10.0 - distance
if result < 0:
return 0
return result
def gaussian_weight(distance):
''' 基于高斯函数的权重 '''
return math.e**(-distance**2 / 3.0**2)
if __name__ == '__main__':
dot1 = [1, 1.2, 5]
dot2 = [2, 1.2, 3]
distance = get_euclidean_distance(dot1, dot2)
print inverse_weight(distance)
print subtraction_weight(distance)
print gaussian_weight(distance)
运行结果如下:
0.309016994375
7.7639320225
0.573753420737
自然,这些方法不只能用在欧几里得距离上,还可以推而广之。
资料
[1] http://zh.wikipedia.org/wiki/高斯函数