2014-09-06
摘要: 回顾了平均值、期望、方差、标准差、协方差及其意义、正太分布,并给出了matlab相关函数。
平均值和期望
对n个数字[latex]x_{1}、x_{2}、...、x_{n}[/latex],算术平均值是:
[latex]
\bar{x} = \frac{1}{n}\sum_{k=1}^ {n}x_{k} [/latex]
在算术平均值中,每个数字对平均值的贡献是相同的。算术平均值是加权平均值的一个特例。设[latex]x_{1}、x_{2}、...、x_{n}[/latex]这n个数对应的权重分别是[latex]w_{1}、w_{2}、...、w_{n}[/latex],那么这些数字的加权平均值是:
[latex]
\bar{x} = \frac{x_{1}w_{1}+x_{2}w_{2}+...+x_{n}w_{n}} {w_{1}+w_{2}+...+w_{n}} [/latex]
在维基百科中给出了这样一个关于加权平均值的例子:一个年级有很多班级,只知道每个班级的人数和分数的平均值,如何求整个年级的分数的平均值?其实在这个问题里,班级的人数就是权重。
在概率论中有期望值的概念,这其实也是一种加权平均。
如果X是一个离散的随机变量,输出值为[latex]x_{1}, x_{2}, ...,[/latex],这些输出值对应的概率分别是[latex]p_{1}, p_{2}, ...[/latex](概率和为1)。那么X的期望值是:
[latex]
E(X) = \sum_{i=1}p_{i}x_{i} [/latex]
再次引用一下维基百科中的例子。
掷一枚六面骰子,其点数的期望值是3.5,计算如下:
[latex]
E[X] = 1*\frac{1}{6} + 2*\frac{1}{6} + 3*\frac{1}{6} + 4*\frac{1}{6} + 5*\frac{1}{6} + 6*\frac{1}{6} \\
=\frac{1+2+3+4+5+6}{6} =3.5 [/latex]
这其实也就是对1,2,3,4,5,6这6个数求权重都为1的情况下的加权平均值。
方差
标准差,又叫均方差、标准偏差。对于[latex]x_{1}、x_{2}、...、x_{n}[/latex],其标准差为:
[latex]
\sigma = \sqrt {\frac{1}{n}\sum_{i=1}^{n}(x_{i}-\bar{x})} [/latex]
方差就是标准差的平方,同标准差一样用来描述一组数据的离散程度,在概率论中就是用来描述一个随机变量的离散程度。
关于方差,有有偏和无偏之分,在知乎的为什么样本方差(sample variance)的分母是 n-1?有讨论,下面整理一下。
上面的关于标准差的公式中右边平方根号里的分母是n,在概率论中这是样本对总体的有偏估计(把样本的方差当做总体的方差,但是有偏差),而当分母是n-1时认为是无偏估计。一致性是指样本的方差和总体的方差是一致的,要达到这样的一致性,样本的数量应该较大。而无偏性是指样本估计量(在这里方差)的期望等于总体的相应估计量。
分别定义总体和样本的一些概念(针对离散型随机变量):
研究对象的全体叫做总体,是一个随机变量,此处用X表示。 随机变量的数学期望:
设离散型随机变量X的分布律为[latex]P{X=x_{i}} = p_{i} (i=1,2,3,...),则随机变量X的数学期望是:
[latex]
E(X) = \sum_{i=1}^{\infty}p_{i}x_{i} [/latex]
随机变量的方差:
[latex]
D(X) = Var(X) = E{[X-E(X)]^2} = E(X^2) - [E(X)]^2 [/latex]
n个相互独立且与总体X同分布的随机变量[latex]X_{1},X_{2},...,X_{n}[/latex]叫做来自总体X的,容量为n的样本。若[latex]x_{1},x_{2},...,x_{n}[/latex]是[latex]X_{1},X_{2},...,X_{n}[/latex]的观测值,[latex]x_{1},x_{2},...,x_{n}[/latex]也叫做样本值。
样本均值: [latex]
\bar{X} = \frac{1}{n}\sum_{k=1}^ {n}X_{k} [/latex]
样本方差:
[latex]
S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_{i}-\bar{X})^2 \\
= \frac{1}{n-1}( \sum_{i=1}^{n}X_{i}^2-n\bar{X}^2 ) [/latex]
样本标准差: [latex]
S = \sqrt {\frac{1}{n-1}\sum_{i=1}^{n}(X_{i}-\bar{X})^2} [/latex]
重点来了,设总体X的数学期望[latex]E(X) = \mu[/latex],方差[latex]D(X) = \sigma ^2 [/latex]。有样本均值的期望等于总体的数学期望,样本均值的方差等于总体方差除以观测值数量,即:
[latex]
E(\bar{X}) = E(X) = \mu; \\
D(\bar{X}) = \frac{D(X)}{n} = \frac{\sigma ^2}{n}; [/latex]
证明如下:
[latex]
E(\bar{X}) = E(\frac{X_{1}+X_{2}+...+X_{n}}{n}) \\
=\frac{E(X_{1})+E(X_{2})+...+E(X_{n})}{n} \\
= \frac{n\mu}{n} \\
= \mu; [/latex]
[latex]
D(\bar{X}) = D(\frac{X_{1}+X_{2}+...+X_{n}}{n}) \\
= \frac{1}{n^2}D(X_{1}) + \frac{1}{n^2}D(X_{2}) + ... + \frac{1}{n^2}D(X_{n}) \\
= \frac{1}{n^2}n\sigma ^2 \\
= \frac{1}{n}\sigma ^2; [/latex]
令:
[latex]
S_{1}^{2} = \frac{1}{n}\sum_{i=1}^{n}(X_{i}-\bar{X})^2; \\
S_{2}^{2} = \frac{1}{n-1}\sum_{i=1}^{n}(X_{i}-\bar{X})^2; [/latex]
可以证明:
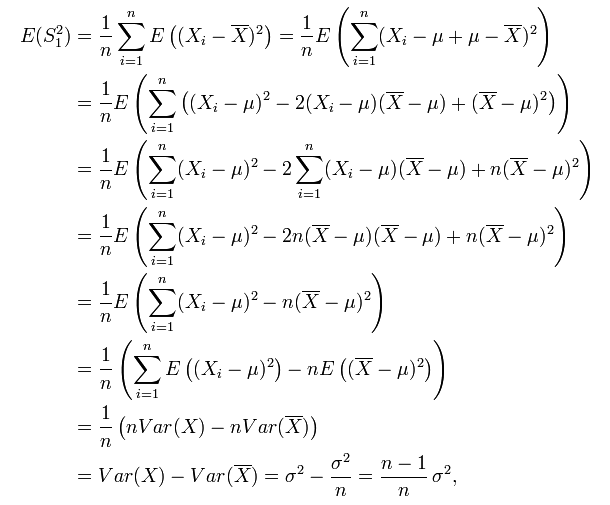
故有:
[latex]
E(S_{2}^2) = E(\frac{n}{n-1}S_{1}^2) \\
= \frac{n}{n-1}E(S_{1}^2) \\
= \frac{n}{n-1}\frac{n-1}{n}\sigma ^2 \\
= \sigma ^2 [/latex]
所以,[latex]S_{1}^{2}[/latex]是对总体方差的有偏估计,[latex]S_{2}^{2}[/latex]是对总体方差的无偏估计。
协方差
随机变量的方差是:
[latex]
Var(X) \\
= E{[X-E(X)]^2} \\
= E{[X-\mu]^2} \\
= E(X^2) - [E(X)]^2; [/latex]
方差亦可当作是随机变量与自己本身的协方差,即:
[latex]
Var(X) = Cov(X,X) [/latex]
所以可以认为方差是协方差的一种特殊情况,即当两个变量是相同的情况。那么什么是协方差,定义如下:
协方差(Covariance):在概率论和统计学中用于衡量两个变量的总体误差。
对于随机变量X,Y,协方差为:
[latex]
Cov(X,Y) \\
= E[(X-E(X))(Y-E(Y))] \\
= E(XY) - E(X)E(Y) [/latex]
假设有n个随机变量[latex]X_{1},X_{2},…,X_{n}[/latex],可以构造它们的协方差矩阵:
[latex]
\begin{equation} \Sigma = \left( \begin{array}{cccccc} Cov(X_{1},X_{1}) & Cov(X_{1},X_{2}) & \ldots & Cov(X_{1},X_{n}) \\ Cov(X_{2},X_{1}) & Cov(X_{2},X_{2}) & \ldots & Cov(X_{2},X_{n}) \\ \vdots & \vdots & \ddots & \vdots \\ Cov(X_{n},X_{1}) & Cov(X_{n},X_{2}) & \ldots & Cov(X_{n},X_{n}) \\ \end{array} \right) \end{equation} [/latex]
很明显,协方差矩阵是一个对称矩阵。
协方差可以用来判别两个变量的相关性。对于随机变量X、Y,其协方差Cov(X,Y)若为正值,则X与Y正相关;为0,则不相关(不相关并不是相互独立);若为负值,则X与Y负相关。注意,正相关的意思是:自变量增长,因变量也跟着增长。
相关程度可以用相关系数来描述:
[latex]
\rho_{X,Y} = \frac{Cov(X,Y)}{\sqrt{Var(X)}\sqrt{Var(Y)}} [/latex]
正态分布(高斯分布)
正态分布,也叫高斯分布。若一个随机变量X的期望为[latex]\mu[/latex],方差为[latex]\sigma ^2[/latex],则认为该随机变量服从正态分布,记做:
[latex]
X \sim N(\mu, \sigma ^2) [/latex]
上面描述的是单变量正态分布,可以据此向多变量正态分布扩展。具体可以参考:Multivariate normal distribution。在多变量正态分布中,涉及到协方差。
matlab实战
求平均值:
>> mean([1 2 3 3])
ans =
2.2500
求标准差的无偏估计:
>> std([1 2 3 3])
ans =
0.9574
求标准差的有偏估计:
>> std([1 2 3 3], 1)
ans =
0.8292
求方差的无偏估计:
>> var([1 2 3 3])
ans =
0.9167
求方差的有偏估计:
>> var([1 2 3 3], 1)
ans =
0.6875
求两组变量的协方差矩阵:
>> cov([1 2 3 3; 2 3 1 5]')
ans =
0.9167 0.4167
0.4167 2.9167
生成单变量的正态分布数据: 要求期望为0,标准差为1,2000个数字。
>> result = normrnd(0,1,2000,1);
>> mean(result)
ans =
0.0257
>> std(result)
ans =
0.9948
生成双变量的正态分布数据: 变量X期望为0,方差为1;变量Y期望为0,方差是100;X与Y的协方差为0;共2000组数据:
X = [];
Y = [];
for i = 1:2000
a = mvnrnd([0,0],diag([1,100]));
X = [X, a(1)];
Y = [Y, a(2)];
end
plot(X,Y, '.');
xlim([-60 60]);
ylim([-60 60]);
得到图形如下: 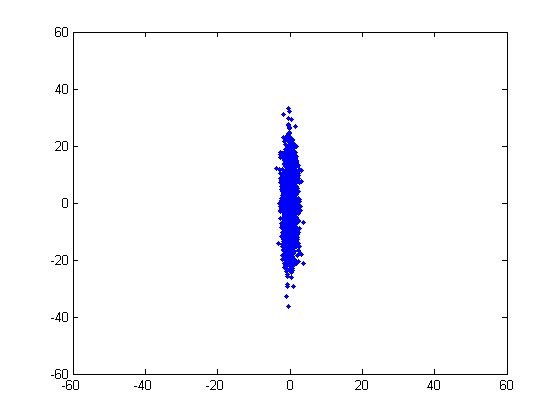
验证一下:
>> mean(X)
ans =
-0.0228
>> mean(Y)
ans =
-0.1074
>> cov([X; Y]')
ans =
1.0215 -0.3402
-0.3402 96.7394
如果需要X与Y的协方差为6,则代码如下:
X = [];
Y = [];
for i = 1:2000
a = mvnrnd([0,0],[1,6; 6,100]);
X = [X, a(1)];
Y = [Y, a(2)];
end
plot(X,Y, '.');
xlim([-60 60]);
ylim([-60 60]);
得到图形: