2014-12-23
在下面的这篇论文里:
Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788-791.
论文中使用了2429张人脸图像,每个图像大小是19×19=361。
以图像重建为例对比了NMF、PCA和VQ。
关于NMF: 隐语义模型和NMF(非负矩阵分解)
关于PCA:使用PCA处理MNIST数据集
VQ,全称Vector Quantization,可以翻译成“矢量量化”。在下面的两个博客里给出了很好的介绍:
漫谈 Clustering (番外篇): Vector Quantization
语音信号处理之(三)矢量量化(Vector Quantization)
NMF
NMF将非负矩阵V分解为两个非负矩阵的成绩,即W×H。设V的大小是n×m,W大小是n×r,H大小是r×m。这篇论文里,目标是最大化下面的式子:
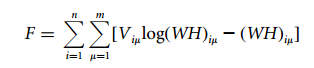
论文中给出下面的式子迭代更新W和H:
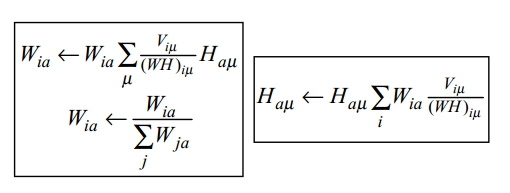
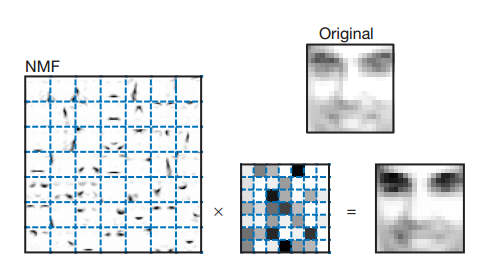
使用论文中的图像数据集,W的大小为361×2429。r设置为49,所以W的大小为361×49,H的大小为49×2429。W的每一列可以构造出一个19×19的图像,但与PCA不同的是,它们是parts-based representations。于是由W可构造49张图片。H的第i列与图片数据集中的第i个图片对应。H(j, i)代表图像i针对图像W(:, j)的权重。这些权重都是非负的。
下图展示了某个图像在NMF下的重建结果:
VQ
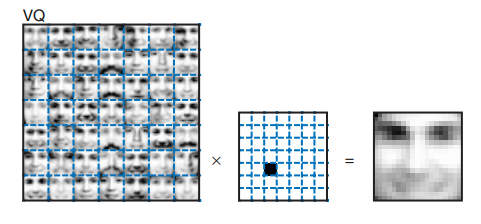
由于NMF中r=49,使用VQ时,将2429张人脸图像使用kmeans聚成49个簇,每个簇的所有图像求centroid,可以得到49个基本图像。重建某个人脸图像时,重建结果是该图像所属的簇的centroid对应的图像。
下图展示了某个图像(和上面的NMF使用同一个图像)在VQ下的重建结果:
PCA
使用PCA将这些图像降到49维度,可以得到49个“特征脸”,对这49个“特征脸”加权求和可以得到一张“原始的脸”(原始图像)。
下图展示了某个图像(和上面的NMF使用同一个图像)在PCA下的重建结果:
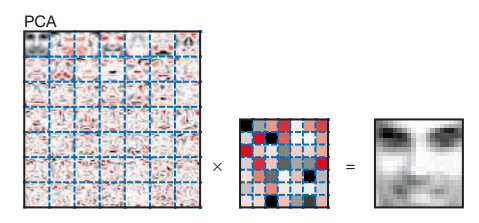
PCA与NMF的一个不同是PCA的权重有正有负。另外一点是,NMF构造的49张图像,每一张展示的是脸的部某分,每张图像是稀疏的;而PCA的每张“特征脸”都显示出了脸的轮廓。