2014-03-14
本文讲述DBSCAN的matlab实现,笔者使用的是Matlab R2012b。请在资料[1]的链接中下载源码DBSCAN.M。
1、先解决一个错误
源代码若以DBSCAN.M为文件名,使用时会出现以下错误:
>> x=[randn(30,2)*.4;randn(40,2)*.5+ones(40,1)*[4 4]];
>> [class,type]=dbscan(x,5,[])
Cannot find an exact (case-sensitive) match for 'dbscan.m'
The closest match is F:\project\clustering\DBSCAN.M
To change the file extension, cd to the file's folder, type:
movefile DBSCAN.M DBSCAN.m_bad; movefile DBSCAN.m_bad DBSCAN.m
and then cd back.
将DBSCAN.M更名为dbscan.m即可。
2、示例
将dbscan.m放入当前工作区间,
>> x=[randn(3,2)*.4;randn(4,2)*.5+ones(4,1)*[4 4]]
x =
0.0092 -0.1143
-0.1048 -0.3325
-0.7001 -0.3917
3.4218 4.2600
3.7332 3.9900
2.9987 3.9826
4.4821 3.6009
>> [class,type]=dbscan(x,3,2)
class =
-1 -1 -1 1 1 1 1
type =
-1 -1 -1 1 1 1 1
>> [class,type]=dbscan(x,2,2)
class =
1 1 1 2 2 2 2
type =
1 1 1 1 1 1 1
>> [class,type]=dbscan(x,2,[])
class =
1 1 1 2 2 2 2
type =
1 1 1 1 1 1 1
数据集x含有7个2维的数据点,函数dbscan有三个参数,第一个参数是数据集;第二个参数是核心对象应该满足的其邻域内最少的数据点的个数;第三个参数用来指定邻域半径,如果值为[],则函数自己判断半径。返回值中class是来标识每个数据点的所属簇的编号,编号从1开始,0表示尚未被分类,-1表示该数据点是噪声,type用来表示数据点是否分类了,0表示未被0表示尚未被分类,-1表示噪声,1表示已经分类。 由x本身的特点可以看出,dbscan(x,2,2)和dbscan(x,2,[])都达到了效果;dbscan(x,3,2)因为第二个参数选的不好,效果不好。
3、分析dbscan.m
下面是dbscan.m去掉大部分注释后的内容:
% -------------------------------------------------------------------------
% Function: [class,type]=dbscan(x,k,Eps)
% -------------------------------------------------------------------------
% Input:
% x - data set (m,n); m-objects, n-variables
% k - number of objects in a neighborhood of an object
% Eps - neighborhood radius, if not known avoid this parameter or put []
% -------------------------------------------------------------------------
% Output:
% class - vector specifying assignment of the i-th object to certain
% cluster (m,1)
% type - vector specifying type of the i-th object
% -------------------------------------------------------------------------
% Example of use:
% x=[randn(30,2)*.4;randn(40,2)*.5+ones(40,1)*[4 4]];
% [class,type]=dbscan(x,5,[])
% clusteringfigs('Dbscan',x,[1 2],class,type)
% -------------------------------------------------------------------------
function [class,type]=dbscan(x,k,Eps)
[m,n]=size(x);
if nargin<3 | isempty(Eps)
[Eps]=epsilon(x,k); %分析可能的邻域半径Eps,关于函数epsilon,见下面的论述
end
x=[[1:m]' x]; %为每个数据点添加编号,其实是合并两个矩阵
[m,n]=size(x);
type=zeros(1,m);
no=1;
touched=zeros(m,1); %标记某数据点是否已被访问
for i=1:m
if touched(i)==0;
ob=x(i,:);
D=dist(ob(2:n),x(:,2:n)); %使用下面的dist函数生成针对当前点的距离矩阵
ind=find(D<=Eps); %见下面的论述
if length(ind)>1 & length(ind)<k+1
type(i)=0;
class(i)=0;
end
if length(ind)==1
type(i)=-1;
class(i)=-1;
touched(i)=1;
end
if length(ind)>=k+1;
type(i)=1;
class(ind)=ones(length(ind),1)*max(no);
while ~isempty(ind)
ob=x(ind(1),:);
touched(ind(1))=1;
ind(1)=[];
D=dist(ob(2:n),x(:,2:n));
i1=find(D<=Eps);
if length(i1)>1
class(i1)=no;
if length(i1)>=k+1;
type(ob(1))=1;
else
type(ob(1))=0;
end
for i=1:length(i1)
if touched(i1(i))==0
touched(i1(i))=1;
ind=[ind i1(i)];
class(i1(i))=no;
end
end
end
end
no=no+1;
end
end
end
i1=find(class==0);
class(i1)=-1;
type(i1)=-1;
%...........................................
function [Eps]=epsilon(x,k)
% Function: [Eps]=epsilon(x,k)
% Input:
% x - data matrix (m,n); m-objects, n-variables
% k - number of objects in a neighborhood of an object
[m,n]=size(x);
Eps=((prod(max(x)-min(x))*k*gamma(.5*n+1))/(m*sqrt(pi.^n))).^(1/n);
%............................................
function [D]=dist(i,x)
% function: [D]=dist(i,x)
% Input:
% i - an object (1,n)
% x - data matrix (m,n); m-objects, n-variables
%
% Output:
% D - Euclidean distance (m,1)
[m,n]=size(x);
D=sqrt(sum((((ones(m,1)*i)-x).^2)'));
if n==1
D=abs((ones(m,1)*i-x))';
end
3.1、epsilon函数如何分析出可能的邻域半径r(或者是Eps)
epsilon函数中有调用了4个函数,max和min用来获取矩阵每一列的最大、最小值,prod将矩阵的每一列进行列内相乘。示例:
>> x=[1 3 ; 2 4]
x =
1 3
2 4
>> max(x)
ans =
2 4
>> min(x)
ans =
1 3
>> prod(x)
ans =
2 12
gamma函数有两个重要的特性,若n为正整数,那么gamma(n) = (n-1)!,另外一个特征就是它与pi的关系:
gamma(1/2) = pi.^(1/2)
gamma(3/2) = 1/2*(pi.^(1/2))
gamma(5/2) = 3/4*(pi.^(1/2))
...
详细请参考资料[2]。
为了更好的理解,对下面的代码(或者说是等式)进行变换:
Eps=((prod(max(x)-min(x))*k*gamma(.5*n+1))/(m*sqrt(pi.^n))).^(1/n);
把Eps换成r方便些:
r=((prod(max(x)-min(x))*k*gamma(.5*n+1))/(m*sqrt(pi.^n))).^(1/n);
最终变换:
r.^n * sqrt(pi.^n) / gamma(.5*n+1) * (m / k)= prod(max(x)-min(x)) %(公式1)
公式1中r代表邻域半径,n是数据的维度,m是数据点的个数,k是核心对象的邻域内至少应具有的数据点数。
在二维空间中,n=2,公式左边r.^n * sqrt(pi.^n) / gamma(.5*n+1)代表半径为r的圆的面积;假定所有核心对象的邻域互相没有交集,m/k则是各个核心对象的个数,也是最终的不想交的由邻域构成的圆的个数。公式右边则代表着这样一个矩形的面积:矩形的各个边平行于横坐标轴或者纵坐标轴,切这个矩形是能涵盖所有数据点的最小矩形。由此可见公式1的合理性。同理,n的值更大时,也有相同的结论。所以,epsilon函数求得的邻域半径是合理的。
3.2、距离矩阵与find函数
dbscan.m中查找数据点邻域中数据点的方法是使用距离矩阵,find函数用来查找符合某个条件的索引,例如:
>> a = [4,2,5,3,9,7]
a =
4 2 5 3 9 7
>> find(a>7)
ans =
5
>> find(a>3)
ans =
1 3 5 6
>> a = [4,2,5 ; 3,9,7]
a =
4 2 5
3 9 7
>> find(a>3)
ans =
1
4
5
6
4、可视化聚类结果
要可视化聚类结果很简单,笔者实现了一个可视化2D数据聚类结果的函数:
% -------------
% 输入:
% data:数据集
% class:每个数据点的分类,-1表示噪点,分类从1开始
% -------------
function color_cluster(data, class)
color_theme = {'ro','g+','bx','ks','r+','go','k*','r+','gv','bs','k+', ...
'rv','gx','bo','kx','rs','gs','b+','ko',...
'rx','g+','bv','kv'};
non_class_color = 'b*'; %噪点
[m, n] = size(data);
subplot(1,2,1);
plot(data(:,1),data(:,2),'ko');
title('raw data');
subplot(1,2,2);
for x = 1:m
if class(x) == -1
plot(data(x,1),data(x,2) ,non_class_color)
else
plot(data(x,1),data(x,2) ,cell2mat(color_theme(class(x))))
end
hold on;
end
title('result');
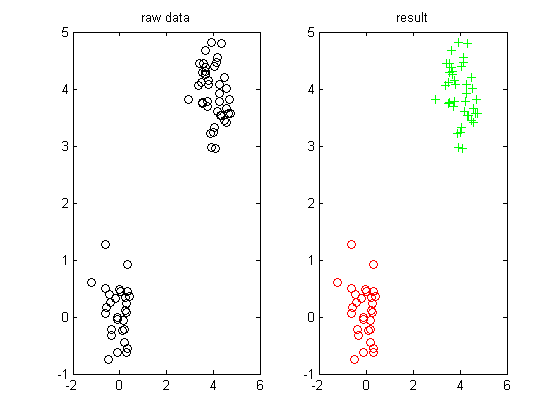
我们测试一下:
x=[randn(30,2)*.4;randn(40,2)*.5+ones(40,1)*[4 4]];
[class,type]=dbscan(x,5,[]);
color_cluster(x,class);
结果如下:
5、资料
[1] DBSCAN的matlab实现 https://code.google.com/p/dmfa07/downloads/detail?name=DBSCAN.M
[2] Γ函数 http://zh.wikipedia.org/wiki/Γ函数