2014-03-26
如何判定相似度是协同过滤的重要内容。在实际应用中很很多方法来获取两组数据之间的相似度,基本原则都是,相似度越大,对应的值也越大。本文总结了一些常用的方法。其中的一些计算使用python完成。
曼哈顿距离
资料[2]定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。 如果在平面直角坐标系中有两个点(1,3)和(13,42),要求两者的曼哈顿距离,应该:
def get_L1(dot1, dot2):
''' 曼哈顿距离'''
return sum([abs(dot1[x] - dot2[x]) for x in range(len(dot1))])
if __name__ == '__main__':
dot1 = [1, 3];
dot2 = [13, 42];
print get_L1(dot1, dot2)
运行结果是51。
一般认为两个点越相似,曼哈顿距离越小(且不会小于0),考虑到距离为0的情况,相应的相似度应该如下计算:
similarity = 1.0 / (1.0 + get_L1(dot1, dot2))
欧几里得距离
这个就是在欧几里得空间两点的直线距离,若两点分别为(1,3,3)和(13,42,13)。
from math import sqrt
def get_euclidean_distance(dot1, dot2):
''' 欧几里得距离'''
s = sum([pow(dot1[x] - dot2[x], 2) for x in range(len(dot1))])
return sqrt(s)
if __name__ == '__main__':
dot1 = [1, 3, 3];
dot2 = [13, 42, 13];
distance = get_euclidean_distance(dot1, dot2)
print distance
求得的欧几里得距离为42.0119030752。与曼哈顿距离类似,相似度可以如下计算:
similarity = 1.0 / (1.0 + get_euclidean_distance(dot1, dot2))
Jaccard/Tanimoto系数
该方法主要用来判断两个集合之间的相似度,说白了就是交集元素个数除以并集元素个数,例如:
def get_tanimoto_coefficient(set1, set2):
''' Jaccard/Tanimoto系数 '''
intersection = set1 & set2
union = set1 | set2
return float(len(intersection)) / len(union)
if __name__ == '__main__':
set1 = set([1,2,3,4,5,33,5])
set2 = set([2,5,34,21,3,7,23,8,0])
print get_tanimoto_coefficient(set1, set2)
结果为0.25。这也就是set1和set2的相似度。资料[9]中给出了一个公式:
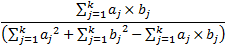
在这个公式中,a和b的每一个值只能是0或1。
余弦相似性
把要判断相似性的两组数据看做两个向量,两个向量夹角的余弦值可以看做这两组数据之间的相似性。相似性结果在[-1,1]区间中,小于0为负相关,大于0为正相关,0为不相关,绝对值越大,越相关(相似)。示例如下:
from math import sqrt
def get_cosine(dot1, dot2):
''' 夹角的余弦值 '''
ab = sum([dot1[x]*dot2[x] for x in range(len(dot1))])
a2 = sum([dot1[x]**2 for x in range(len(dot1))])
b2 = sum([dot2[x]**2 for x in range(len(dot2))])
return float(ab)/sqrt(a2)/sqrt(b2)
if __name__ == '__main__':
dot1 = [1,0]
dot2 = [0,1]
print get_cosine(dot1, dot2)
运行结果为0.0。
关于余弦相似性,更多请参考资料[6]。
皮尔逊相关系数
皮尔逊相关系数用来做相关性(相似性)计算,其结果同余弦一样,也在区间[-1,1]中。在资料[7]中能够找到下面这个公式:
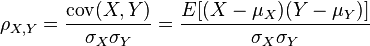
分子是X和Y的协方差,分母是X的标准差乘Y的标准差。
在实际计算中,可以这样计算:
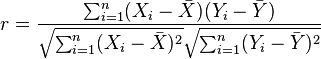
在资料[8]中也提到了皮尔逊相关系数。
资料
[1] 協同過濾
[2] 曼哈頓距離
[3] Euclidean distance
[4] Jaccard/Tanimoto系数
[5] http://stn.spotfire.com/spotfire_client_help/hc/hc_tanimoto_coefficient.htm
[6] 余弦相似性
[7] 皮尔逊相关系数
[8] Correlation and dependence
[9] Tanimoto Coefficient