2014-09-18
偏导数与梯度
有时候,遇到的数学公式会有多个变量,例如:
[latex]
f(x,y) = x+x^2+y^2 [/latex]
将变量y看做常量,对x进行求导,可得:
[latex]
1+2x [/latex]
这个结果可以就是f(x,y)关于x的偏导数,可以写成:
[latex]
\frac{\partial f}{\partial x} = 1+2x [/latex]
同理,可以得到f(x,y)关于y的偏导数: [latex]
\frac{\partial f}{\partial y} = 2y [/latex]
我们画一下f(x,y)的mesh图:
%% matlab
x=-10:0.1:10;
y=x;
[X,Y]=meshgrid(x,y);
Z = X + X.^2 +Y.^2;
mesh(X,Y,Z);
xlabel('x');
ylabel('y');
zlabel('z');
结果如下: 
说白了,偏导数就是斜率。以点(x,y,z)=(1,1,3)为例,我们找到过点(1,1,3)且与x轴、z轴都平行的那个唯一的平面,曲面f(x,y)与这个平面相交得到一曲线。这个曲线在y=1处的斜率就是f(x,y)在点(1,1)处关于y的偏导数的值。
如果把f(x,y)这个多元函数退化成一元函数f(x),只能得到一个偏导数,且就是斜率。
将[latex]\frac{\partial f}{\partial x}[/latex]和[latex]\frac{\partial f}{\partial y}[/latex]整合起来,称作梯度。
梯度指明了局部范围内在哪个方向上函数增长最快,可以用来快速的得到局部最大值/最小值。
梯度上升和梯度下降
换个抛物线函数作为示例: [latex]
f(x) = x^2 [/latex]
有: [latex]
\frac{\partial f}{\partial x} = 2x [/latex]
plot下f(x):
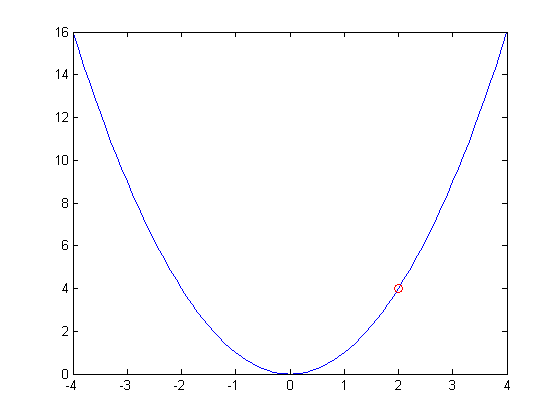
当x=2时,f(x)=4,对于这个点,关于x的偏导数的值为4,即梯度为4,也就是说如果x沿着+4的方向改变,那么f(x)的值将增大,这就是梯度上升;相反,如果x沿着-4的方向改变,那么f(x)的值将减小,这意味着我们可以通过这种方式来得到f(x)的最小值以及相应的x,这就是梯度下降和它的意义。当然,如果将f(x)关于x轴反过来,梯度上升可以帮助我们得到最大值。
现在只说梯度下降。一般,开始时随机地选择一个种子点,从这个种子点开始,种子点沿着其梯度的相反方向下降。下降的方向是可以求的,下降的程度(即“步长”)需要根据经验指定,例如x下降的方向是-4,步长可以是0.1,于是x会由2变成2-0.1*4=1.6。这个过程需要重复多次,当觉得已经达到最小值的目标时,就可以结束了。可以通过下面的方法判断是否达到目标:
- 迭代次数达到指定的值。
- 相邻的两次的结果达到某个可以允许的误差范围。
- 下一次的运行结果大于这一次的运行结果。
- 梯度非常接近0时。
下面理一下[latex]f(x) = x^2[/latex]使用梯度下降法时迭代的过程(假定步长一直为0.1):
- x=2,梯度为2*2=4。
- x=2-0.1*4 = 1.6,梯度为2*1.6 = 3.2。
- x = 1.6 - 0.1*3.2 = 1.28,梯度为2*1.28 = 2.56。
- ……
注意,考虑到一个函数可能有多个极小值/极大值,以及种子点是随机选取的,用梯度上升/下降法得到的结果只能说是局部最优。
梯度下降也可以用来解非线性函数,请移步http://en.wikipedia.org/wiki/Gradient_descent。
使用梯度下降法训练线性单元
假设在一个平面上有两类点,可以用一条直线将它们划分开来,那么如何求这根直线?如果是高维空间中有两类点可以用一个超平面(类似二维空间的线)区分开,如何求这个超平面?
在二维空间中,直线的表达式是:
[latex]
w_{1}x_{1}+w_{2}x_{2}+b = 0 [/latex] 其中,[latex]x_{1}, x_{2}[/latex]分别代表一个维度,[latex]w_{1}, w_{2}[/latex]是权重,b是偏置项,线性回归的目的是求得权重和偏置项。
将这个公式延伸到n维空间,就变成了寻找合适的超平面: 在二维空间中,直线的表达式是:
[latex]
w_{1}x_{1}+w_{2}x_{2}+...+w_{n}x_{n}+b = 0 [/latex]
假设我们将这些点所属的类分别叫做类+1和类-1,其实我们要找的就是这样一个函数:
[latex]
O(\vec{x}) = \vec{w}\vec{x} +b =\sum_{i=1}^{n}w_{i}x_{i} + b [/latex]
向量[latex]\vec{x}[/latex]代表n空间中的一个点。[latex]O(\vec{x})[/latex]若大于0,则认为[latex]\vec{x}[/latex]属于类+1的可能性较大,若小于0,则属于类-1的可能性较大。
令[latex]x_{0}=1, w_{0}=b[/latex],那么可以将上面的[latex]O(\vec{x})[/latex]简化为:
[latex]
O(\vec{x}) = \vec{w}\vec{x} +b =\sum_{i=0}^{n}w_{i}x_{i} [/latex]
这相当于给[latex]\vec{x}[/latex]增加了一个维度,且值都为1。
我们需要一个标准来衡量计算出的[latex]\vec{w}[/latex]的好坏,一般可以采用平方误差:
[latex]
E(\vec{w}) = \frac{1}{2}\sum_{d \in D}(t_{d}-o_{d})^2 [/latex]
D是数据集合,[latex]t_{d}[/latex]是点d的目标输出(即类别-1或者+1),[latex]o_{d}[/latex]则是我们计算出的类别(但这个类别可能是小数,例如0.2,代表更有可能是+1类)。很明显,上面的公式是关于向量[latex]\vec{w}[/latex]的二次函数,所以必然有一个确定的[latex]\vec{w}[/latex],是的平方误差最小。
在开始时,给权重向量中的每个权重一个随机值,接着,我们要找出这个向量的每个值应该沿着哪个梯度的负方向前进。
以[latex]w_{i}[/latex]为例:
[latex]
\frac{\partial E}{\partial w_{i}} \\
= \frac{\partial}{\partial w_{i}} [\frac{1}{2}\sum_{d \in D}(t_{d}-o_{d})^2] \\
= \frac{1}{2}\sum_{d \in D}\frac{\partial}{\partial w_{i}}(t_{d}-o_{d})^2 \\
= \frac{1}{2} \sum_{d \in D} 2 (t_{d}-o_{d}) \frac{\partial}{\partial w_{i}}(t_{d}-o_{d}) \\
= \sum_{d \in D}(t_{d}-o_{d}) \frac{\partial}{\partial w_{i}}(t_{d}-\vec{w} \vec{x}_{d}) \\
= \sum_{d \in D}(t_{d}-o_{d}) (-\vec{x}_{di}) [/latex]
其中,[latex]\vec{x}_{di}[/latex]是向量[latex]\vec{x}_{d}[/latex]的第i个分量,是一个标量。由上面的求导结果可以看出,对于[latex]w_{i}[/latex],要最小化[latex]E(\vec{w})[/latex],[latex]w_{i}[/latex]需要朝下面的方向前进:
[latex]
\sum_{d \in D}(t_{d}-o_{d})\vec{x}_{di} [/latex]
我们把已被分类的点记做[latex]<\vec{x}, t>[/latex],[latex]t[/latex]是[latex]\vec{x}[/latex]的类别(class),设步长为[latex]\eta[/latex],这里步长也可以叫做学习率。综上,可以得到相应的梯度下降算法:
// 梯度下降
将[latex]\vec{w}[/latex]中的每个权值[latex]w_{i}[/latex]取随机值;
WHILE 没有达到某个终止条件之前 DO {
初始化每个[latex]\Delta w_{i}=0[/latex];
FOR 每个已分类的数据点[latex]<\vec{x}, t>[/latex] DO {
根据公式[latex]O(\vec{x}) = \sum_{i=0}^{n}w_{i}x_{i}[/latex],计算[latex]\vec{x}[/latex]的目标输出[latex]o[/latex];
对于每个[latex]\Delta w_{i}[/latex],更新为[latex]\Delta w_{i}=\Delta w_{i}+\eta (t-o)x_{i}[/latex];
}
对每个[latex]\Delta w_{i}[/latex]进行更新,即[latex]w_{i} = w_{i} + \Delta w_{i}[/latex]
}
上面的梯度下降算法有两个问题:
1、收敛过程可能很慢 2、E(w)存在一个最小值,但也可能存在存在多个极小值,上面的算法不一定能找到最小值。
为了缓解上面提出的问题,可以使用增量梯度下降算法(也叫随机梯度下降算法):
//增量梯度下降
将[latex]\vec{w}[/latex]中的每个权值[latex]w_{i}[/latex]取随机值;
WHILE 没有达到某个终止条件之前 DO {
FOR 每个已分类的数据点[latex]<\vec{x}, t>[/latex] DO {
根据公式[latex]O(\vec{x}) = \sum_{i=0}^{n}w_{i}x_{i}[/latex],计算[latex]\vec{x}[/latex]的目标输出[latex]o[/latex];
对于每个[latex]w_{i}[/latex],更新为[latex]w_{i}=w_{i}+\eta (t-o)x_{i}[/latex];
}
}
注意:数据点的类别也可以使用其他数字表示,梯度下降也可以用于多类问题。