2014-12-23
什么是PCA
假设要将n维空间中的数据降低到m维(m < n)。首先在n维空间中找一个点作为m维空间的坐标原点O,然后找到m个n维的向量,这些向量的原点是O。将n维的数据对应的点投影到这m个向量上,可以将n维数据降低到m维。
设一个n维数据点X(i),将其投影到m维空间后的点在n维空间的位置记为Y(i)。如果有k个n维的数据,PCA的目标是最小化下面的式子:
[latex] \sum_{i=1}^{k} (X(i)-Y(i))^2 [/latex]
在一系列的计算后,扯到了协方差矩阵的特征值和特征向量上。
这就是PCA。
**补充:**上面的式子叫做投影误差。PCA是将投影误差最小化。其实PCA也在最大化一个方差。这个方差是原始数据集在新的低维度空间对应的所有的数据点之间的方差。
数据集准备
在数据堂下载的手写数字数据集MNIST,已经被预处理了。解压后可以找到mnist_all.mat,该文件存储了图片的数据。每个图片大小是28×28=784。
用哪些图片呢?
在Matlab中导入mnist_all.mat,然后:
imgs = [train0(1:10, :);
train1(1:10, :);
train2(1:10, :);
train3(1:10, :);
train4(1:10, :)];
imgs = im2double(imgs);
for i = 1:50
subplot(5, 10, i);
imshow(reshape(imgs(i, :), 28, 28));
end
效果如下:

每个图片大小为28×28=784,共有50张图片。故imgs大小为:
>> size(imgs)
ans =
50 784
PCA一下
[coeff,score,latent] = pca(double(imgs));
size(coeff)
size(score)
latent
结果如下:
ans =
784 49
ans =
50 49
latent =
1.0e+05 *
6.0345
3.4149
2.7540
2.6989
2.0999
1.8697
1.4234
1.3323
1.2419
1.0725
...
...
latent从大到小保存了样本协方差矩阵所有的特征值。coeff的每一列是样本协方差矩阵的特征向量(主成分分量),并与latent中的特征值一一对应。score第i行前n个数值代表着样本i降到n维的结果。在这个例子中,协方差矩阵共有49个特征值。
取前两维,并可视化:
plot(score(1:10, 1), score(1:10, 2), 'r*');
hold on;
plot(score(11:20, 1), score(11:20, 2), 'g*');
hold on;
plot(score(21:30, 1), score(21:30, 2), 'b*');
hold on;
plot(score(31:40, 1), score(31:40, 2), 'go');
hold on;
plot(score(41:50, 1), score(41:50, 2), 'ro');
hold on;
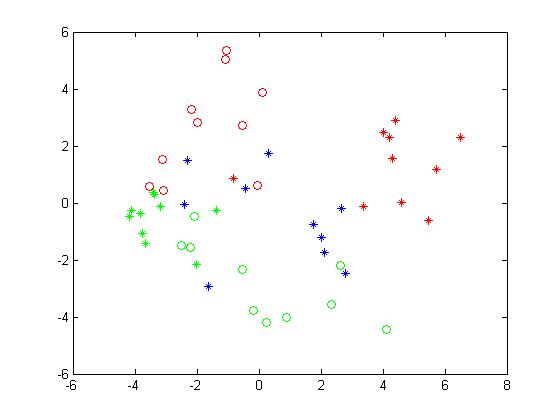
可视化“特征脸”
“特征脸”这个词出现在使用PCA处理人脸数据集的相关文章中,在这里我借用一下。
主成分分量coeff大小为784×49,每一列可以构造一个“特征脸”。下面,对这些特征脸可视化:
for i=1:49
subplot(7, 7, i);
imshow(reshape(coeff(:, i), 28, 28));
end
效果如下:

不太清楚,反转一下:
for i=1:49
subplot(7, 7, i);
imshow(1.0 - reshape(coeff(:, i), 28, 28));
end
效果如下:

重建图像
score第i行前n个数值代表着样本i降到n维的结果。score第i行的第j个数值代表着第j个“特征脸”在原图像i中的权重。这些权值有正有负,例如:
>> score(:,1)
ans =
4.0235
4.2079
3.3788
4.3208
6.4901
4.3880
5.7397
-0.8090
5.4659
4.5928
-3.3578
-3.6533
...
...
据此,可以重构图像。下面以第一张图像为例。
计算样本均值:
base_img = mean(imgs);
imshow(reshape(base_img, 28, 28));
结果如下:
使用前2个“特征脸”重建第一个图片:
base_img = mean(imgs);
img = base_img';
for i = 1:2
img = img + coeff(:, i).*score(1, i);
end
imshow(reshape(img, 28, 28));
结果如下: 
使用前10个“特征脸”重建第一个图片,结果如下:

使用前30个“特征脸”重建第一个图片,结果如下:
