2014-05-15
前些日子参加了搜狗赞助的一个比赛,主题是万维网上的实体关系提取。
记得这学期刚开学的时候还屁颠屁颠的搞了几天,最终因为精力原因就没有做下去。自己虽然没做多少但是也值得总结一下,恰好今天比赛截止,也不可能误打误撞扰乱了比赛。
笔者平常并不探索实体关系提取和自然语言处理等内容,所以本文内容更偏向于编程实践。
比赛官网是搜狗-中国数据库学术会议万维网知识提取大赛。
问题描述
主办方提供了较大的数据集,其中参考文档集用于构建知识库(不过官方说可以自己使用其他的其他的资源构建知识库)。数据集都是一堆文本文件,参考文档集的数据格式(即文件每一行的格式)为:
网页的url 正文字节数 正文
正文就是url对应的html。我们的目的是要从这个知识库中提取出类似下面的实体关系:
中国合伙人 演员 黄晓明
言简意赅,就是得到正确的两个实体之间的关系。
实体必须是来自官方提供的实体数据集,这个数据集对应的文本文件每一行代表一个实体,格式为:
Id Name Class Description
其中ID是唯一的;Name就是实体的名称,例如黄晓明;Class是实体的分类,共书籍、歌曲、人物、电影、电视剧这5类;Description是对这个实体的简单描述。
而关系也必须是来自官方的关系模式集,一共18个关系,包括
人物\t父母\t人物
歌曲\t演唱者\t人物
歌曲\t作词\t人物
电影\t演员\t人物
书籍\t作者\t人物
人物\t夫妻\t人物
.....
\t是制表符。注意,关系是有向的,例如A的父亲是B,那么实体关系是A\t父母\tB,不能倒过来写。
参赛者的最终结果格式如下:
实体ID 关系 实体ID 参考URL
真正提交时使用制表符分隔。例如
中国合伙人的id\t演员\t黄晓明的id\thttp:// movie.douban.com/subject/11529526/
评价方式如下:
对于每一个关系模式,计算一个F值,计算公式为2/(1.5/准确率+0.5/召回率),公式会略偏重于准确率。准确率为0时,F值为0。所有关系模式的F值的算术平均值为参赛队的总体得分。
工具选择
python、MongoDB(MySQL太慢),如果做下去,不排除后期使用Mapreduce方式解决问题。
思路
笔者首先从参考文档集中提取出这些文档来自于哪些网站,笔者统计结果是25个,如下:
baike.baidu.com
www.hudong.com
novel.hongxiu.com
www.qidian.com
www.youku.com
book.douban.com
weibo.com
......
这些网站对应的文档数目也有差别的,例如www.hudong.com有文档68000左右,而www.17k.com有文档2000左右。
由于HTML本身属于半结构化的文档,所以我的主要思路是根据HTML结构尽可能能的找出实体关系,事实上这25个网站除了百科之外都能够很细致的找到实体以及实体间关系,但是每个网站都要写一两个处理工具来提取。
以http://book.douban.com/subject/1000286/为例,下图是该网页的截图,请注意圈画的部分:
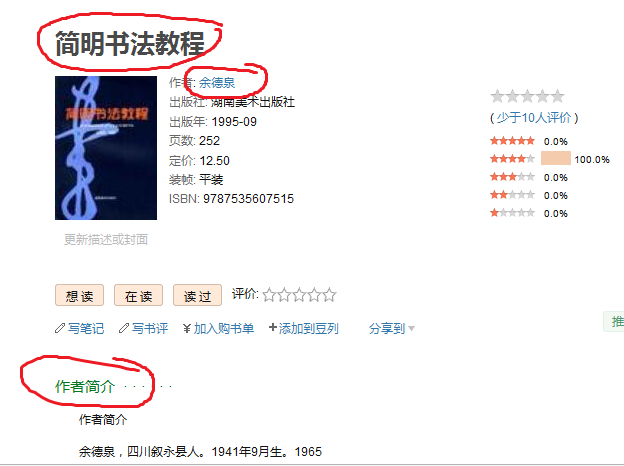
很容易能找到简明书法教程\t作者\t余德泉这一实体关系,当然这些只是前期的数据提取,后期可能要用到作者简介这一信息。之所以可能要用到作者简介这一信息,是因为在实体书籍集中有实体重名的问题,也就是说,可能有两个余德泉,一个是搞书法的,顺便写写教程,另外一个可能是著名演员,这时候就要用到一些附加信息了,例如这个网页中的其他内容,实体数据集中的Class和Description属性。笔者使用Python的BeautifulSoup库操作HTML,当然也有其他很多优秀的库可以选择,例如pyquery。
比较难搞的是www.hudong.com、baike.baidu.com等百科网站,百科数据很难用上面的方法提取实体关系。所以有两种可能,一是这些是噪声数据,二是这是得高分的关键。这里说一个简单的方法:
- 如果实体A和实体B同时出现在一篇文章中,那么A和B可能具有某种实体关系;
- 如果A是一个人,B是一本书,那么A可能是B的作者(之一)。
- 假设A出现在B之前,而两者之间有“写作”、“书写”等类似词语,那么A是B的作者的可能性就更大了。
其实就是建立一个概率模型。鉴于数据量比较大,可能要用到一些优化技术来加快处理速度。另外,中文分词也可能会被使用。
以上就是我的一点思路。
吐槽几句
- 虽然奖金优厚,比赛宣传不够,截止2014-5-15 22:05:09只有90个团队注册。
- 比赛网站很粗糙,至少让我觉得比赛不正规。
- 比赛数据很大,且可以划分为较多情况(按照笔者的思路是这样子的),而很多情况下的数据提取又纯粹是体力活;另外,参赛者如果设备精良,可以省些运行时间。
以上吐槽纯粹个人想法。
补充(2015-01-04)
这个比赛的题目与知识图谱相关,知识图谱涉及到的内容很多。