2015-05-26
本文是下面这篇论文的阅读笔记:
Ma C C. A Guide to Singular Value Decomposition for Collaborative Filtering[J]. 2008.
注意,这里的SVD,和经典的分解为3个矩阵的方法是不一样的。
提出问题
直接使用传统的SVD进行协同过滤的的效果可能会很差,所以考虑一些SVD的变体来进行协同过滤。
用户可以对电影评分,分数范围是1到5。一般,一个用户不会给所有的电影都评分,有些用户评分的电影很多,有些用户只给很少的电影打评分。
一般评分矩阵中的0代表着对应的用户没有给对应的物品(电影)评分,0并不能看作分值。
设[latex]V[/latex]是大小为n×m的评分矩阵,n个用户,m个电影。[latex]I[/latex]也是大小为n×m的矩阵,其元素的值只有0和1,若[latex]I_{ij}[/latex]为1,则用户i给物品j打过分,这也意味着[latex]V_{ij}[/latex]不为0;若[latex]I_{ij}[/latex]为0,则用户i没给物品j打过分,这也意味着[latex]V_{ij}[/latex]为0。故矩阵[latex]I[/latex]是矩阵[latex]V[/latex]的指示器(indicator)。矩阵[latex]V[/latex]也可以以稀疏矩阵的形式保存,只保存打过分的数据。
矩阵[latex]V[/latex]作为协同过滤算法的训练数据,而协同过滤算法的目标是预测某个用户对某个物品的评分(该用户之前没有对该物品评分)。
算法的评测标准:一般是比较真实评分和预测的评分之间的误差,例如Mean squared error、Root Mean Squared Error。
算法1:Batch learning of Singular Value Decomposition
设n个用户,m个物品,n×m大小的矩阵[latex]V[/latex]是评分矩阵,大小为n×m的矩阵[latex]I[/latex]作为[latex]V[/latex]指示器。SVD算法的目标是找到两个矩阵:f×n大小的[latex]U[/latex]作为用户的特征矩阵,f×m大小的[latex]M[/latex]作为物品的特征矩阵。预测函数[latex]p[/latex]根据[latex]U[/latex]和[latex]M[/latex]预测评分。
[latex]V_{ij}[/latex]的预测值为:
[latex] p(U_{i}, M_{j}) [/latex]
其中,[latex]U_{i}[/latex]为用户i的特征向量(feature vector,不是eigenvector,f个元素),[latex]M_{j}[/latex]为物品j的特征向量(f个元素),这两个特征向量从矩阵[latex]U[/latex]和[latex]M[/latex]中直接拿就行了。
然后,我们要最小化下面的式子: 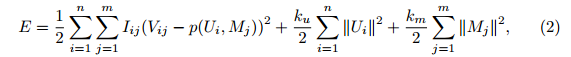
其中,[latex]k_{u}[/latex]和[latex]k_{m}[/latex]是防止过拟合的正则化系数,是两个已知的擦书,需要我们自己事先指定。
函数[latex]p[/latex]的一般实现如下:
[latex] p(U_{i}, M_{j}) = U_{i}^{T}M_{j} [/latex]
就是两个向量的内积(数量积)。
不过,V中的评分是在[a,b]这个范围里,其中a是最小的评分,b是最大的评分。所以预测函数优化为:

好了,现在对于公式(2),[latex]I,V,n,m,p,k_{u},k_{m}[/latex]都是已知的,通过最小化公式(2)就可以得到[latex]U和M[/latex]。
可以用梯度下降解决这个问题,下面两个式子是负向的梯度:
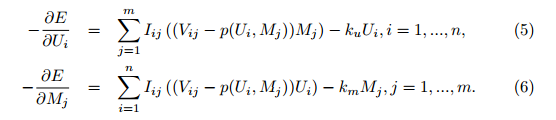
而梯度很明显是:
[latex] \nabla{U_{i}} = \frac{\partial{E}}{\partial{U_{i}}} \\ \nabla{M_{j}} = \frac{\partial{E}}{\partial{M_{j}}} [/latex]
由此,得到下面的算法:
- 给矩阵U、M赋初始值(例如使用随机值),建议使用下面的方法赋值:
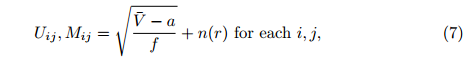
其中,[latex]\bar{V}[/latex]是指V中评分的平均值,a是i所有评分的最小值,f是用户和物品在新特征空间下的维度,n(r)是基于区间[-r, r]生成均匀分布的随机数,r取一个较小的值就行了。
- 设置学习速率[latex]\mu[/latex],重复下面两个步骤直到评估方法RMSE的值开始上升:
(a). 计算梯度[latex]\nabla{U}和\nabla{M}[/latex]
(b). 更新U和M:[latex]U\leftarrow U- \mu \nabla{U},~~M\leftarrow M- \mu \nabla{M}[/latex]
迭代停止的判断条件可以有很多,例如RMSE基本不变,或者U、M基本不变时停止迭代。
批量学习(Batch learning)是SVD的标准方法。
算法2:Incomplete incremental learning of Singular Value Decomposition
对用户i,目标函数是: 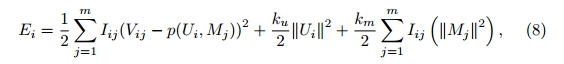
负方向梯度为:
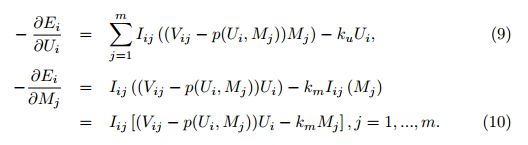
对于用户i来说,如果[latex]I_{ij}=0[/latex],即用户i未对物品j评分,则[latex]M_{j}[/latex]的梯度为0,不会造成M的更新。
算法如下:

算法3:Complete incremental learning of Singular Value Decomposition
这个方法中的目标函数,以及对应的负方向梯度如下: 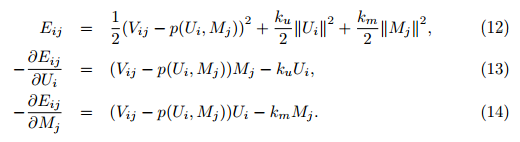
算法如下: 
算法4:Batch learning of SVD with Momentum
这是对算法1的修改:

更多
Ma C C. A Guide to Singular Value Decomposition for Collaborative Filtering[J]. 2008.
本文的内容都来自这篇论文,论文中Further Improvements章节还提到了在目标函数中添加针对用户和物品的偏置向量,在得到U和M的同时,得到偏置向量,这种方法的评估效果会更好些。
Paterek A. Improving regularized singular value decomposition for collaborative filtering[C]//Proceedings of KDD cup and workshop. 2007, 2007: 5-8.
里面提到了若干基于SVD的算法,还提到了一些有趣的协同过滤算法,例如基于聚类的协同过滤算法。
Funk, Simon. "Netflix update: Try this at home." (2006).
放在博客里的一篇有名的文章。
Koren, Yehuda. "Factorization meets the neighborhood: a multifaceted collaborative filtering model." Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2008.
SVD++就在这里。 关于SVD++: SVD++ - recsyswiki、 推荐系统常用模型(2) – SVD/SVD++、 What's the difference between SVD and SVD++?。
Koren, Yehuda. "The bellkor solution to the netflix grand prize." Netflix prize documentation 81 (2009).